You, I, and even John next door know that machine learning has made your machines “smarter” by predicting future outcomes, using the data fed to them. ML.NET is the de facto standard in .NET for machine learning, that allows you to train models upfront and make predictions accurately.
Let’s suppose you have an ML.NET application for predicting taxi fares, based on previous trips data and current traffic. Given the current COVID-19 pandemic, we have seen a massive shift in consumer behavior: long-distance traveling is minimized, more deliveries are being made to drop off food/grocery, some areas are cordoned off completely, and so on. The incoming data for this application is rapid and changing continuously, so the machine learning model is retrained frequently. If the Machine Learning side reads this data, it can cause slowdowns.
To tackle such issues, you need to cache your trip data so that data is accessible to the ML.NET application without any bottlenecks. ML.NET provides default caching, but that is not scalable. NCache is an in-memory, distributed cache in .NET. Using NCache for data processing increases application performance as it provides fast read/write operations as it is in-memory. Being distributed, NCache can scale on runtime if the data sets become too large.
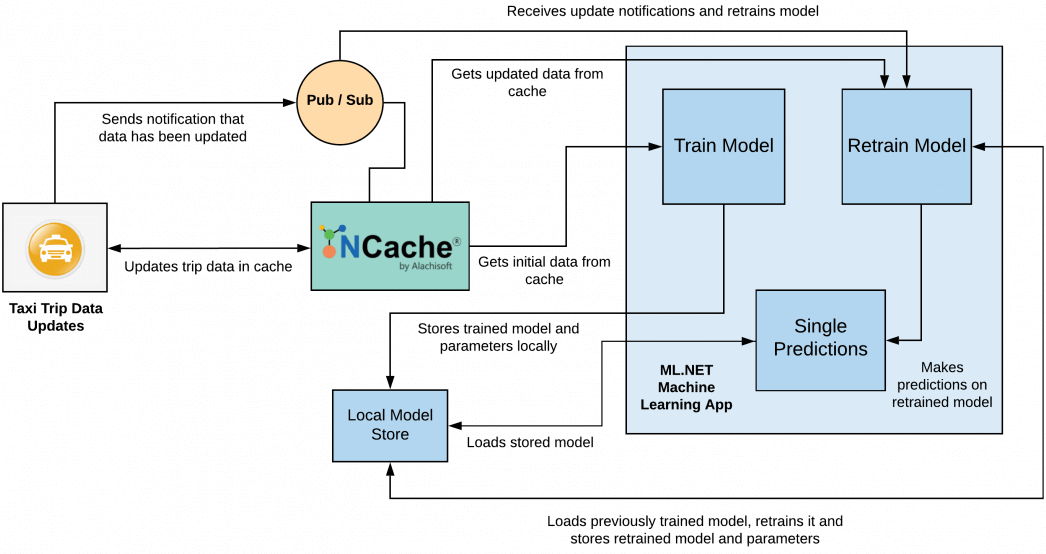
Figure 1: ML.NET model with NCache for Taxi Fare Prediction
Using NCache to Scale and Retrain Machine Learning Models
To depict how NCache can make this ML.NET application more scalable and retrain models faster on runtime, we have extended the widely used TaxiFarePrediction project by Microsoft to integrate NCache. You can find this extended project with NCache on GitHub.
The application works like this, as illustrated above in Figure 1:
- The taxi trip data is stored in the cache as a List data type which is an extension of
IEnumerable IList. ML.NET supportsLoadFromEnumerable()method, so no extra manipulation of the data is necessary. - The ML.NET application subscribes to the Pub/Sub topic to receive updates when more data chunks of the specified size are added to the cache.
- For the initial data set, the data (stored as a List) is fetched by the ML.Net application to train the machine learning model. After training, the model is stored in a local model store and caches the model path.
- Once a new data chunk is added to the cache, Pub/Sub notifies the retraining model application of the data update. When the application gets any new data, a part of the previous chunk of data is removed, based on the sliding window concept. In this, the first part of the previously used data is removed according to the length of the new dataset. This trimmed data is merged with the new data and added into the cache. Now, this chunk of data and the already trained model will be used while retraining of the new model.
- After each training/retraining of the model, single value predictions are made on the transformed data to test model accuracy.
NCache Details NCache Machine Learning GitHub Solution
Using Data Structures to Cache Trip Data
NCache offers IEnumerable distributed data structures, that make it very simple for ML.NET to directly fetch and read data because of ML.NET’s support for LoadFromEnumerable(). The data can be conveniently stored in a List data type and loaded directly into the ML.NET model for training.
The following code snippet shows how data can be stored in the cache using List data structures.
NCache Details NCache Machine Learning GitHub Solution
Fetching In-Memory Data to Train Model
To initially train the ML.NET model, the application first fetches the data stored as a List data type from NCache. The model is trained based on StochasticDualCoordinateAscent (SDCA) regression algorithm and saved in the form of a .zip file for later use. These saved files are used for retraining models in the future. The model path is also cached to be used later.
Using Pub/Sub Notifications on Data Update to Retrain Model
Using NCache’s Pub/Sub, events are triggered to the application to retrain data as more data is updated in the cache. The ML.NET application subscribes to the NCache topic for notifications about the data being updated. If data is updated in the cache, NCache Pub/Sub notifies the application that data has been updated, and data is retrained.
Sliding Data with Lists for Retraining Model
Once new data is added to the cache, the training data is populated using the sliding window concept to fetch the latest data. This keeps a chunk of the previous data in the list along with the new data. Once the data is updated, a message is published to the subscribers using NCache’s Pub/Sub mechanism so that retraining can take place. The model and pipeline are loaded from the .zip files and retrained according to the ML.NET retraining algorithm.
Step 1: Slide Data and Notify via Pub/Sub
Step 2: Load Trip Data from Cache and Retrain Model
NCache Details NCache Machine Learning GitHub Solution
To Sum It Up…
Usually, when data is processed for machine learning, it is asynchronously loaded so the training models load data from disk and execute their algorithms several times over it. Hence, caching datasets in-memory with NCache helps reduce unnecessary loading of data from disk and makes it easier to notify ML.NET applications to start retraining instantly through its Pub/Sub mechanism. Moreover, being distributed, it scales on runtime if the datasets get too large. So, head over to checkout NCache and how it can enhance your machine learning application performance!