As data continues to hold immense value, Apache Lucene has emerged as a leading full-text search engine renowned for its ability to search vast amounts of textual data using inverted indexing efficiently. However, being a standalone solution, Lucene poses scalability challenges as data volumes increase, requiring frequent index rebuilding that can significantly hamper performance. While Java and REST-based alternatives now offer scalable options for full-text search, the .NET stack still lacks a seamlessly integrated, scalable solution for this critical function.
Using Distributed Lucene with NCache for .NET
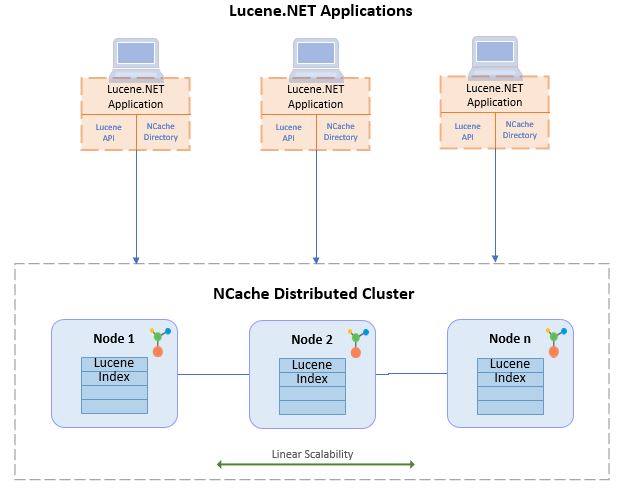
NCache, a powerful and popular .NET in-memory data store, has implemented native Lucene.NET API over its distributed architecture. As it is the standard Lucene.NET API, no code change is required to use it in a scalable manner with NCache.
NCache also utilizes Lucene.NET to create indexes in a dynamically scalable environment to allow distributed full-text searches. The results of these searches merge before being sent back to your application. This enhances the stand-alone Lucene into a fast, linearly scalable full-text searching solution.
This enhances the stand-alone Lucene into a fast, linearly scalable full-text searching solution.
Using Lucene in .NET Apps
Let us consider an e-commerce site that holds information on thousands of products, orders, and customer details. Hence, indexing all attributes especially non-textual fields (which are not used while searching), is not a wise approach, as it exhausts the cache memory.
For example, our document for a product looks like this:
Now, we know that our clients perform full-text searches specifically on the product description field within documents. To optimize this process, we propose indexing only searchable fields and associating them with keys that link back to their corresponding documents in our persistence store, such as a database or file system. For instance, when querying for products like “dishwasher-friendly Tupperware,” all relevant products matching these terms will be retrieved with their ProductID serving as the document key. Subsequently, the complete document can be efficiently fetched from the persisted index, streamlining search operations.
To use Distributed Lucene in your existing applications, all you need is to specify NCacheDirectory when opening a directory. This requires the NCache cache name and the index name. The following code snippet opens a directory on a cache LuceneCache in NCache and an index named ProductIndex.
Lucene ships an extensive query language, which interprets a given string into a Lucene query. This can be done either on a term, multiple terms, wildcards, or even fuzzy words. To learn more about Lucene queries, read Lucene Query Docs.
The following code snippet creates an IndexReader on the directory, which is used by the IndexSearcher. The data is analyzed and tokenized based on the StandardAnalyzer. The first 50 hits from the result are returned to the application. Note that the analyzer must be the same as the one used during index creation.
Load Data to Build Distributed Index
With Lucene, you can build indexes and load data into them as needed. Indexes require an analyzer, that analyzes and tokenizes the data according to your need. This includes whitespace, non-letters, punctuation, and so on. Once you create a writer for your Lucene index, you can create documents and add fields to it. This document is then indexed in NCache as a distributed index once you call Commit(). For more details on Lucene analyzers, have a look at Lucene Analyzer Docs.
Why NCache for Distributed Lucene?
Using NCache for Distributed Lucene provides you with the following benefits:
- Extremely Fast and Linearly Scalable: NCache is an in-memory distributed data store, so building distributed Lucene on top of it provides the same optimum performance for your full-text searches. Moreover, because of NCache’s distributed architecture, the Lucene index is partitioned across all the servers of the cluster. This makes it scalable as you can add more servers on the go as your data load increases, and Lucene indexes are automatically redistributed without any client intervention.
- Data Replication for Reliability and High Availability: With NCache’s Partition-Replica topology, the Lucene index is not only partitioned across all servers but each partition is also replicated to another server of the cluster. Hence, if any server goes down, the replica of the partition serves all the queries for that index, ensuring reliability. Similarly, if a server node goes down, NCache dynamically self-heals by readjusting the data within the remaining nodes, without any downtime or impact to your Lucene index, ensuring high availability.
Conclusion
To sum it up, full-text searching has now become fundamental in almost every business, owing to the powerful search engine Lucene. But as data grows, rebuilding indexes can cause more damage than gain and this is where an in-memory, distributed .NET solution such as NCache steps in. All it requires is a one-line code change in your existing Lucene application, and voila, you have the best of both worlds as an in-memory, distributed full-text search mechanism.




