Python is a popular open-source language known for its dynamic typing and high-level built-in data structures. It is suited well for Rapid Application Development, data analysis, and automation, due to high-level built-in data structures along with dynamic binding and typing. However, as Python applications scale up in size, they tend to experience performance issues that are often due to database load and resource contention.
NCache, a powerful in-memory distributed cache, addresses these problems by keeping frequently accessed data in memory and improves application scalability and performance. It reduces strain on databases while providing fast data retrieval. NCache was initially developed with support for .NET applications but has since expanded to support Java, Node.js, and Python clients. This allows Python applications to utilize advanced caching features like data replication, high availability, partitioning, expiration policies, and advanced querying.
Why Use Distributed Caching in Python Applications?
Distributed caching includes storing frequently accessed data across various in-memory nodes, enabling fast information retrieval without the need to repeat queries to a backend database. This strategy has numerous advantages:
- Reduced Latency & Faster Performance: Using in-memory caching cuts down the need for costly database queries, hence quicker response times.
- Scalability: Unlike single-node caching solutions, a distributed cache can grow horizontally by including more nodes, guaranteeing constant access and efficiently handling more workloads.
- High Availability & Fault Tolerance: Distributed caches maintain data accessibility by replicating it across various nodes, safeguarding against data loss in the event of a node failure.
- Efficient Load Balancing: With capabilities such as partitioning and replication, distributed caching optimizes load distribution among multiple cache servers.
- Reduced Database Load: By storing frequently accessed data, distributed caching alleviates database contention, thereby enhancing overall system performance.
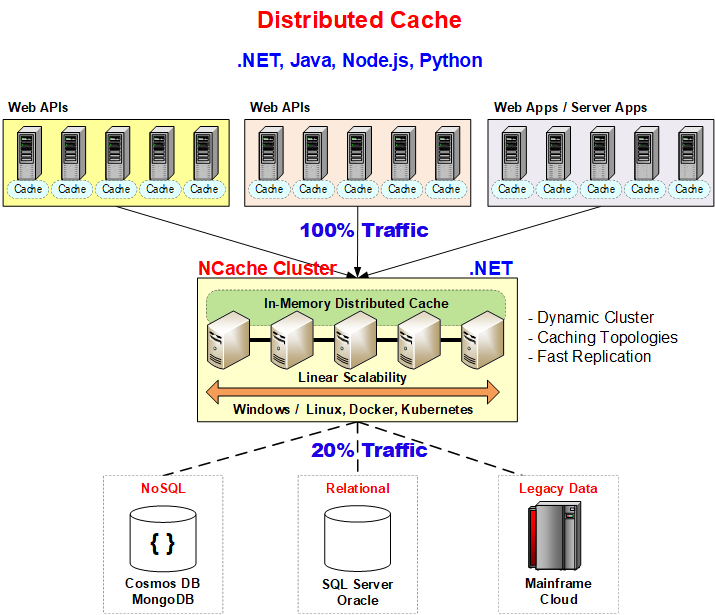
Figure: Distributed cache.
Real-World Use Cases
Below are some key applications where NCache can be used to optimize performance and enhance scalability:
- E-commerce Platforms: By caching product catalogs, shopping carts, and customer session data to offer fast access without many database queries, e-commerce platforms improve user experience.
- Content Delivery Networks (CDNs): By caching media files, static assets, and regularly accessed contents to cut latency and enhance website performance.
- Big Data & Analytics: By storing preparatory datasets, real-time analytics outputs, intermediate computation results, and other data to accelerate data handling.
- Real-Time Financial Systems: By caching stock prices, currency exchange rates, and user portfolios to deliver immediate updates and minimize transactional delays.
- IoT & Smart Devices: By storing sensor data at the edge before synchronization with cloud services, which reduces bandwidth consumption and enhances response times in distributed systems.
Setting Up NCache for Python Applications
To incorporate NCache into a Python application, make sure you have Python version 3.7 or later installed. Follow these steps to begin:
Step 1: Installing NCache
NCache is available for Windows and Linux. Refer to the official installation guide for step-by-step instructions.
Scenario 1: Installing Cache Server on a Developer Workstation
For local development, you can run an NCache server using Docker on your workstation:
This command pulls and starts the NCache server container locally. Ensure Docker is installed and running before executing the command.
Scenario 2: Setting Up a 2-Node Cache Cluster on Dedicated Servers
Setting up a 2-node cache cluster ensures high availability and fault tolerance, especially in production or testing environments. Run the following command on each dedicated server:
Once both cache servers are operational, set up clustering using the NCache management tools or command-line utilities. This setup ensures data replication and high availability, preventing single points of failure.
Step 2: Creating a Clustered Cache
To enhance performance and ensure data redundancy; it is advised to establish a clustered cache. An optimal configuration consists of two nodes, as a single-node cache does not offer replication and lacks high availability.
A clustered cache enables several cache servers to collaborate, effectively distributing data and ensuring that cached information remains accessible even if one node fails, thanks to replication. This configuration mitigates bottlenecks and improves scalability, fault tolerance, and load balancing.
To create a clustered cache, you need to:
- Start NCache on each cache server (as outlined in the installation steps).
- Use the NCache Management Center or command-line tools to create a new clustered cache instance.
- Add multiple cache servers (nodes) to the cluster.
- Ensure the cache is started and properly configured before connecting the Python client.
Once the clustered cache is set up, it can handle distributed data efficiently, allowing multiple applications to interact with the cache without performance degradation.
Step 3: Installing & Configuring the Python Client
Use the following command to install the NCache Python client:
Next, import the necessary modules and connect to the cache:
Once connected, the Python application can utilize NCache’s caching features to optimize performance.
Basic Cache Operations in Python
You can perform basic operations in your Python application using NCache as follows:
Adding Data to the Cache
The add method uses the cache-aside pattern, that is, first looking in the cache and only going to the database if the data is not in the cache. If it finds nothing in the cache, it retrieves the data from the database and stores it in the cache with an absolute expiration policy for cleaning old unused data.
Updating/Inserting Data in the Cache
The insert method follows the cache-aside pattern, where the application updates the data in the database first and then updates the cache accordingly. Additionally, absolute expiration can be applied to ensure the cached item is removed after a set duration.
Retrieving Data from the Cache
To retrieve multiple objects at once, use the get_bulk method.
Removing Data from the Cache
To delete multiple objects at once, use the remove_bulk method.
Advanced Caching Features
NCache provides advanced data search capabilities, allowing developers to retrieve data using:
- Groups: Logically group related cache items.
- Tags: Assign simple keywords to cache items for easy retrieval.
- Named Tags: Associate multiple keywords with cached objects for better filtering.
- SQL Queries: Use structured queries to filter cache data efficiently.
- Sliding Expiration: Extends item lifespan based on access frequency.
- Absolute Expiration: Automatically removes an item after a defined period.
- Least Recently Used (LRU) Eviction: Automatically removes least accessed items when the cache reaches its capacity.
Conclusion
Scaling Python programs, improving reaction times, and lessening database load are possible with distributed caching. NCache provides a high-quality, feature-rich solution that enhances availability, reliability, and application performance. Integrating NCache with your Python applications enables effective management of high traffic loads, and fault tolerance through replication and partitioning, and lowers operational expenses by reducing direct database queries. Get NCache now to boost your Python programs using quick, dependable, and scalable distributed caching.