Split-Brain
A Split-Brain occurs when one or more nodes of a cluster experience disconnection from the other nodes resulting in the formation of sub-clusters.
In essence, Split-Brain is a terminology that is based on an analogy with the medical Split-Brain syndrome. This condition depicts the inconsistency in data or its availability that may originate from the maintenance of two separate data sets with overlap in scope. This may be due to the servers in a network design or a failure condition that may be caused due to miscommunication and de-synchronization of data between the corresponding servers in the network. This is also commonly termed as a network partition.
Since NCache is also a distributed cache that can comprise multiple nodes and clusters, the occurrence of Split-Brain is also a possibility with NCache.
When a Split-Brain occurs, there is possibility of sub-clusters being formed. Hence, one of the sub-clusters has to be removed to ensure all clients are redirected on one healthy cluster. Since sub-cluster removal means that data will be lost, the sub-cluster to be removed is selected on the following criteria:
- In case the sub-clusters are of varying sizes, the sub-cluster with the least number of nodes will be removed. This is to ensure minimal data loss, as the smaller cluster will contain lesser data.
- If the size of the clusters is same, the sub-cluster whose coordinator node has the higher IP address will be removed. For example, the IPs of coordinator nodes of sub-cluster A and B are 20.200.20.38 and 20.200.20.40 respectively. In this case, the sub-cluster with coordinator node IP 20.200.20.40 will be removed.
A Split-Brain may represent data inconsistency or availability issues stemming from the maintenance of two separate data sets with overlap in scope. Also, this may also lead to significant problems and can pose a dire situation for the administrator. For this reason, it is highly important to make sure that there is no risk of Split-Brain and data corruption.
There are some common approaches to deal with the network partition issue after a Split-Brain is incurred.
- Optimistic Approach
- Pessimistic Approach
In the Optimistic Approach, the communication channel between the nodes is simply restored while letting the partitioned nodes work as usual temporarily. This is done assuming that the nodes will synchronize automatically in a short time. This approach may be just an easy way out as there is always a threat of data corruption in case of Split-Brain.
On the other hand, the Pessimistic Approach requires letting go of or simply sacrifice systems availability in order to keep data consistent. On detection of a network partitioning, access to the sub-partitions is limited. This is done to ensure data consistency. In this case, in order to circumvent history divergence, only one component can continue to make read/write requests to the storage.
Handling Split-Brain through NCache
When a Split-Brain occurs, the cluster nodes in the network undergo a series of checks before making important decisions such as which nodes are to shut down, restart and reconnect or be removed from the network. NCache provides a feature called Split-Brain Auto-Recovery, which is by default disabled. However, it can be enabled on the basis on data sensitivity and user requirements in case a Split-Brain occurs in the network.
NCache offers this feature only for the Partition of Replica topology. In order to understand this in depth, let’s have a look at cluster connectivity, Partition of Replica topology and scenarios behind node disconnection.
Cluster Connectivity
Two or more nodes work connect and work together to form a cluster. Each node of the cluster is called a member. A cluster in NCache can be considered as a group channel in which members can talk to each other by sending or receiving messages. A cluster is always formed in a mesh topology, which means that all nodes are interconnected.
Each cluster comprises of one coordinator node and the remaining non-coordinator or participant nodes. The coordinator node is the most senior node i.e. the node that started first and is responsible for most of the tasks, such as node addition or removal. Whenever a node is added or removed from cluster, it informs the coordinator node, which manages the rest of the operations to maintain a connectable environment in cluster. Other tasks that the coordinator node carries out include bucket distribution, triggering cache loader and connections maintenance.
A cluster can be categorized as follows:
- Fully connected cluster
- Partially connected cluster
- Stopped
Fully Connected Cluster
A cluster is termed to be in a fully connected state if a cluster has n nodes and each node in the cluster has healthy n-1 connections with all other nodes. In this state, all of the nodes can communicate with each other, hence it is in stable state.
The following figure shows a fully connected cluster in an ideal state.
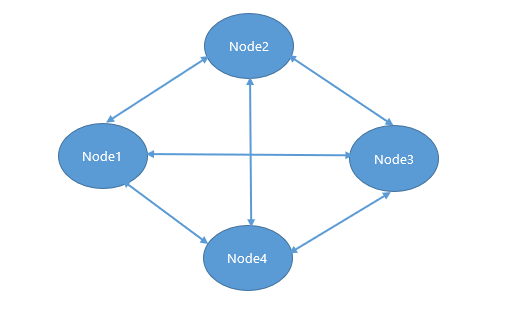
If a cluster is in a fully connected state and a node joins the cluster, it becomes a part/member of the corresponding cluster. If a node leaves the cluster or is partially disconnected, with one or more member nodes, it forms a separate cluster. All the existing nodes are informed of this change in the network by the coordinator node. This triggers State transfer, which is aimed at balancing the data in the new cluster. Based on the topology, the client connections are distributed among new nodes.
Client Connectivity
If a cluster is in healthy state, in the PoR topology, all the clients are connected with all nodes of the cluster. In case of Split-Brain, which is relevant to the Partitioned Replica (PoR), clients are connected to all nodes of cluster. If a node joins, the clients connect to the new node as well. If a node leaves, the client can continue to perform the operations.
Stopped
If a node leaves the cluster properly, i.e. it has been shut down and there is no host process for the corresponding node, then the node is considered as stopped with respect to rest of the cluster. Stopping a node results in State Transfer, which leads to balancing of data. This, in turn, balances the number of clients among the rest of the nodes. However, this feature is specific to the REP topology.
Client Connectivity
Clients that were connected previously to the stopped node will now connect to other connected nodes.
Partially Connected Cluster
There may be situations where one or more nodes of a cluster are unable to connect to other nodes, for example due to a network glitch.
Let’s suppose, there is a 3-node fully connected cluster. If a glitch occurs such that two of the three nodes can still communicate with each other, however, the third node cannot reach the network, then the two connected nodes will form a single sub-cluster, say sub-cluster 1. The third, disconnected node will form an independent sub-cluster, say sub-cluster 2. Each sub-cluster will now have its own coordinator nodes. In this situation, the cluster loses its ideal connected state. Now exist two clusters, which cannot communicate with each other, but are fully connected within their sub-clusters. This state is called partial connectivity of a cluster as can be seen in the figure below.
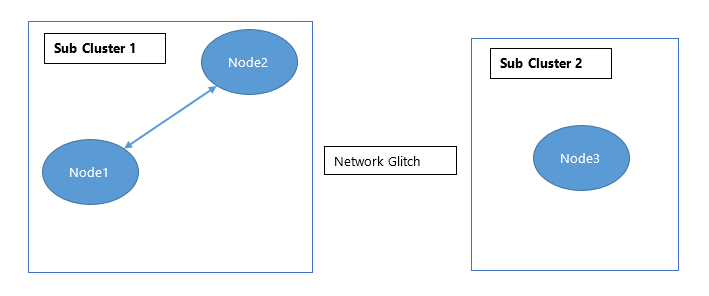
In aforementioned scenario, the nodes in sub-cluster 1 and sub-cluster 2 are such that sub-cluster 1 is fully connected with itself and fully disconnected with sub-cluster 2, and vice versa.
In a more complex case, let’s suppose a 5-node cluster where a network glitch causes node 5 to break its connection from all the nodes except node 3. In this case, node 3 is still connected to node 5, and node 3 is still connected to node 1, node 2 and node 4 as well. Now, node 3 is a common member for sub-cluster 1 (node 1, node 4 and node 2) and sub-cluster 2 (node 5).
The following figure illustrates partial connectivity in progress.
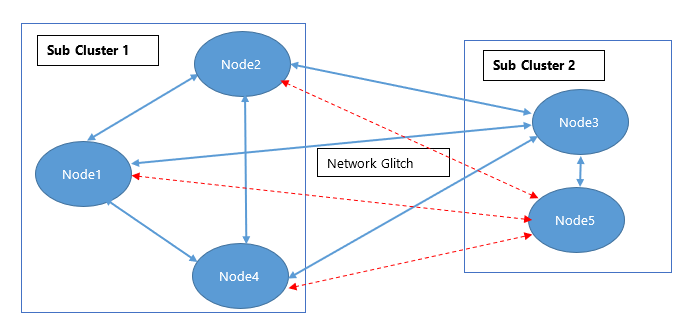
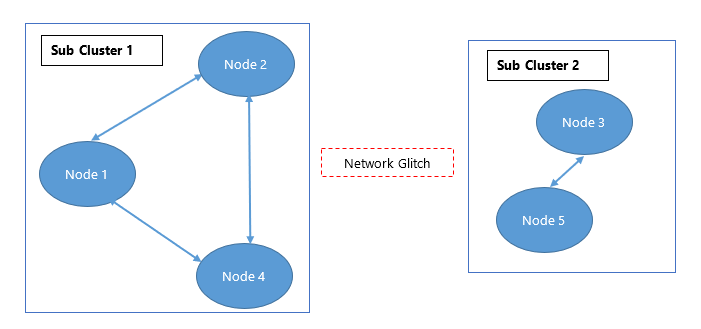
Each cluster will notify Node 3 asking it to maintain its connection to one cluster only. On receiving notifications, node 3 will assess where the notifications are being received from and it will connect to the sub-cluster containing the most senior node before the main cluster disconnection took place, which in this scenario is sub-cluster 2.
The following figure displays partial connectivity of a cluster in its final state.
Connection Retries
Every cluster operation has a Timeout value, which is 60 seconds by default and is configurable in NCache Web Manager. Every cluster has Connection Retries (default value 2) and Retry Interval (default value 2). Both of these values are also configurable in NCache Web Manager.
Whenever a node connection is broken from a cluster, the prevailing coordinator node tries to re-establish the connection first. If the retry results in a successful connection and no timeout occurs, the cluster turns to normal, fully connected state. However, if the connection could not be re-established for some reason, then all the nodes of cluster form multiple sub-clusters resulting in partial connectivity.
New Node Joining
If a cluster is in a partially connected state, any addition of a new node will be done to the part of the sub-cluster that holds appropriate connectivity in the network. In case it is connected with both sub-clusters, it will join the sub-cluster with the greater size i.e. the sub-cluster that has more number of nodes. If number of nodes are equal, it will compare the IPs with the Coordinator node and will join to Coordinator with a greater IP.
Client Connectivity
In case of partial connectivity, as the cluster is in an unstable environment, the client applications may incur abrupt and uncertain behaviors. If a client machine is connected to both sub-clusters, then some of the clients may connect to sub-cluster 1 and others to to sub-cluster 2. There might be a possibility that network connectivity is such that all clients connect to one sub cluster only. There will be no data consistency in cluster as well.
Fix for Partial Connectivity Issue
To resolve the issue of Split-Brain, NCache offers both manual and automatic recovery options as explained below.
Manual Resolution
When a cluster gets into a partially connected state, it needs to be restarted. The first recommendation is to attempt to identify and resolve the problem that caused it to be in this state. If it is due to network issues, attempt to stabilize the network. After fixing the issues, shutdown the nodes creating a single cluster and start them one by one.
For example, consider the cluster in Figure 3. It can be seen that node 1, node 2 and node 4 are fully connected in sub-cluster 1 whereas node 3 and node 5 are fully connected in sub-cluster 2. Since, a network glitch resulted in the creation of the sub-cluster 2, you need to shutdown node 3 and node 5. Try to fix the issue causing the network glitch. Once done, start each node one by one. The started nodes will become a part of the sub-cluster1, which will then turn into a fully connected cluster.
Split-Brain Auto Recovery
In order to cater to Split-Brain, NCache also provides an automatic method, which is the Split-Brain Auto Recovery option through NCache Web Manager. Since data can be of various types and hold different sensitivity levels, by default this option is disabled. It is entirely dependent on the administrator of NCache Web Manager whether or not to enable it as per deemed necessary according to the situation. To enable Split-Brain Auto Recovery for clusters, please see Enabling Split-Brain Auto Recovery using NCache Web Manager.
See Also
Enable Split-Brain Auto-recovery using NCache Web Manager
Configuring Cache Cluster Settings