Lucene Components and Overview
Note
This feature is available in NCache Enterprise and Professional editions.
Lucene, as we know is a powerful and efficient search engine that provides with a vast range of text searching techniques as per user requirements. Lucene is much more than any other text searching engine as the choices given to the user are not discriminated on any basis. It has powerful and strong searching algorithms and supports a wide range of queries for searching.
Lucene applications have a basic cycle which primarily comprises of first indexing data on which searching is performed, at a specific path. The data added can be in any textual form as per the user's needs. Data is indexed and tokenized and then searching is performed on these tokens using queries. This is a two way process as it includes first the processing of data and then searching on it.
The following diagram depicts the basic Lucene model work flow.
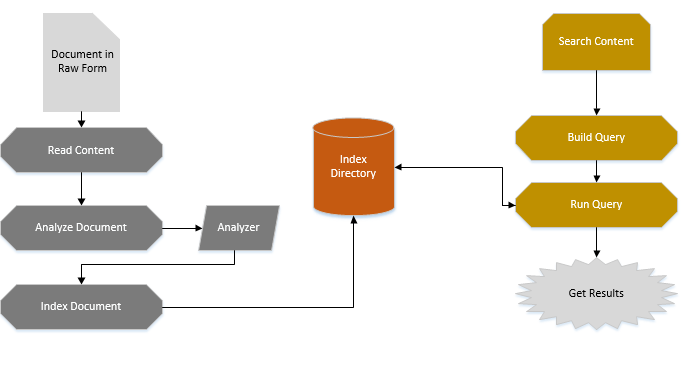
Components of Lucene
In order to use Lucene for text searching, let us take a closer look at the main API used by Lucene. Please note that it is not a complete guide for Lucene. However, it will help you get the understanding of basic and radical Lucene API.
Following is the basic API used to build a Lucene based solution.
Directory: It is the base class that defines where the indexes are formed.
Document: It contains the data that is to be indexed.
Analyzer: While the data is being indexed, the analyzer decides the criteria on the basis of which tokenizing and searching is done on the data. Similarly it is used while querying data which also involves tokenizaion.
IndexWriter: Documents which are created beforehand are passed to the directory using this class. One indexWriter can be opened at a time.
IndexReader: Every directory where index are created may have reader(s) opened on it which is responsible for reading data from the indexes.
IndexSearcher: The searcher is responsible for querying the data through the reader(s).
Given below is the detailed description of these classes:
Directory
This class is a representation of the location where Lucene indexes are stored. A directory needs to be opened for maintaining indexes so that further operations can be performed on them.
Document
A document is a collection of fields. These fields contain textual data as value against a field name. The value is the data that you want to index and then make searchable for future. With every field, user can specify whether he wants to analyze that field value or not. Document is basically the unit of search which will be returned when a field is searched against a searchterm.
Analyzer
Analyzer as discussed earlier has the prime responsibility of tokenizing the data
into smaller chunks as per the type provided. It basically parse the fields of the documents into indexable tokens. The way of data being analyzed by the analyzer influences the user's ability to search the data. Listed below are the four basic and most commonly used Lucene analyzers.
Whitespace Analyzer
This analyzer analyzes the data according to whitespaces as the name shows. Moreover this analyzer maintains the case of the words. It performs the tokenization of data according to the case it primarily contains.
Standard Analyzer
It analyzes the data according to stop words as well as performs tokenization on the data in lower-case similar to the simple analyzer. Additionally it recognizes the URLs and email addresses and generates tokens accordingly. Due to this functionality it is most commonly used as it is considered the most intelligent analyzer.
Simple Analyzer
It indexes the data in lower-case and splits them based on non- letters. It does not index URLs and non-letter characters such as symbols or numbers.
Stop Analyzer
The stop analyzer generates tokens from the data according to the non-letter characters as well as stop words. Stop words are the words that are supposed to be ignored while indexing as the analyzers considers them irrelevant to be scanned through. Moreover the stop analyzer does not index URLs and non-letter characters such as symbols or numbers.
Consider the sentence below:
This is a tutorial for “DistributedLucene” at alachisoft.com.
| Whitespace Analyzer | Stop Analyzer | Simple Analyzer | Standard Analyzer |
|---|---|---|---|
| This is a tutorial for “DistributedLucene” at alachisoft.com. |
tutorial distributedlucene alachisoft com |
this is a tutorial for “distributedlucene” alachisoft com |
tutorial distributedlucene alachisoft.com |
Index Writer
In order to add the document and index it, we need an IndexWriter. Writer needs:
A valid Lucene Directory: where document is to be indexed
Analyzer: so that the writer analyzes the data according to it.
Writer corresponds with the analyzer for the indexed data and then adds the results to the Directory for the storage of the data. Precisely, the writer is responsible for all the write operations to be correctly performed on the data and then store it. There is a set of operations that can be performed on the writer and the writer is disposed after all operations.
Index Reader
The main functionality of Lucene is to search the data added previously. For
this purpose we have IndexReader which reads the data from the directory. On every update in the documents the IndexReader needs to be re-initialized. You can either create an IndexReader or get an instance of IndexReader from the IndexWriter. You pass the directory instance to the reader
which has all the documents indexed.
Index Searcher
IndexSearcheris the initialized with the instance of
IndexReader which takes the query from the user and searches the data
accordingly. A query is an abstract class provided by Lucene and is used to define the scope and type of searching to be performed. On searching we are
returned with TopDocs which is the result of searching with the query.
Now that the query is created, you parse the query using the QueryParser.
Analyzer is passed to the queryParser which parses the query according to that
analyzer. Moreover the fieldname added in the document is passed to the query
searcher so that it searches the data accordingly.
An array is maintained in topDocs which is
known as scoreDocs. ScoreDocs will maintain the search results on the query
execution basis. On iterating over this array, the resultant data can be retrieved.
Recommendation: The analyzer used for searching is recommended to be the same with which the data was indexed in the first place.
See Also
Lucene with NCache
Configure Lucene Query Indexes
SQL Search in Cache
Search Cache with LINQ