DistributedLucene Overview and Usage
Note
This feature is available in NCache Enterprise and Professional editions.
NCache now provides a Lucene module which provides you with an ease of using Lucene for text searching with NCache. You can plug in NCache with your Lucene application to achieve higher level of scalability and optimization.
Note
NCache uses 4.8 Version of Lucene.Net.
Why to Use Lucene with NCache?
Lucene.Net is a standalone text searching engine. The indexes created by Lucene reside on a single node along with the client applications using Lucene. It affects the overall application performance and scalability along with the probability of single point of failure. This is where NCache comes in handy.
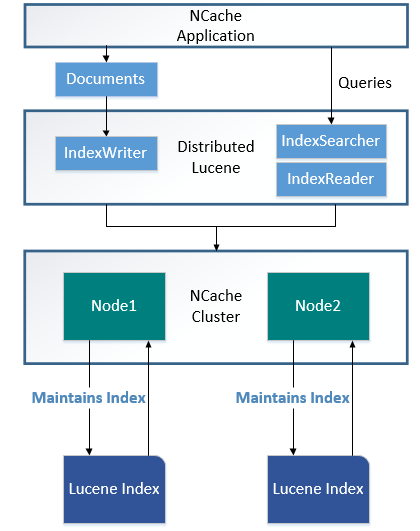
NCache provides a distributed implementation of Lucene with minor changes in it's API. Lucene’s API calls NCache at the backend. Separate indexes are maintained on all the nodes. The more the nodes, the higher the scalability and performance. In case of Partitioned-Replicated cache, indexes are maintained on the replica nodes too which provides fault tolerance. Every cache partition holds memory-mapped based Lucene index. This prevents problems like single point of failure. NCache being distributed in nature, with Lucene provides linear write scalability as the documents indexed by the applications are automatically distributed among cache nodes where they are independently indexed. Similarly DistributedLucene provides a linear read scalability since queries are propagated on each partition and results are merged. A higher number of partitions provides higher amount of read and write scalability.
This is loaded in the context of NCache on cache startup. Due to this, the applications already using Lucene can shift to DistributedLucene with minor code changes.
Working of DistributedLucene
In order to use Lucene for searching the data is first indexed and then search operations are performed on the indexed data. The behavior of Lucene and DistributedLucene is almost same with a few changes.
Note
Please see the section below to see the differences in the behaviors of Lucene and DistributedLucene.
The diagram below shows how DistributedLucene model works.
Pre-Requisites
- Make sure that Lucene is enabled using NCache Web Manager.
- Make sure that Client Notifications are enabled using NCache Web Manager.
Install the Lucene.Net.NCache NuGet package to your application by executing the following command in the Package Manager Console:
Install-Package Lucene.Net.NCache- Make sure that the cache is already running.
- Make sure that your application is not using any native Lucene DLL/Reference.
- To ensure the operation is fail safe, it is recommended to handle any potential exceptions within your application, as explained in Handling Failures.
- To handle any unseen exceptions, refer to the Troubleshooting section.
Important
- This feature is only available in Partitioned and Partitioned Replica cache.
- In case of Developer Installation, local caches can configure DistributedLucene.
Initialize DistributedLucene
NCacheDirectory is used for maintaining the directory of the indexes. In NCacheDirectory the following are passed:
CacheName: The cache name using Lucene
IndexName: Every index is uniquely identified by a name. It creates a directory with the provided index name as there can be multiple indexes on a single cache. (By Default the directory is created at %NCHOME%\bin\modules\data\lucene for Windows and at /opt/ncache/bin/modules/data/lucene/ for Linux, but in case of custom path, it needs to be defined in NCache Web Manager)
The code given below opens NCacheDirectory on the cache named luceneCache.
try
{
// Specify the cache name that is used for Lucene
string cache = "LuceneCache";
// Specify the index name to create the indexes
string indexName = "ProductIndex";
// Create a directory and open it on the cache and the index path
Directory directory = NCacheDirectory.Open(cache, indexName);
}
catch(Exception ex)
{
// Handle Lucene exceptions
}
Indexing Data
Once, the directory is initialized, indexWriter is opened. After creation of indexWriter, documents are
created on the index with the same mechanism as that in Lucene. Since NCache maintains key-value store so for distribution of documents, an autogenerated key is added to each document. The document is indexed on the node against that specific key.
DistributedLucene maintains a queue of the documents at the backend on each node. A background thread writes documents to the index underneath. This makes DistributedLucene scalable and fast for the user since Lucene.Net does not allow parallel writes. In order to get the information about the completion of operations at an instance, NCache introduced a Boolean property IndexWriter.OperationsCompleted which returns true in case no more operations are to be performed and false otherwise.
Note
One index can have one writer opened on it at one time. If you want to open a different writer, the first opened writer on the index must be disposed first.
For any Write operation on the writer we need to call Commit in order to save it. Commit needs to be called or else it won’t save the write operations.
The following code opens an indexWriter on the specified directory and provides with the analyzer to analyze the data according to that.
try
{
// Specify the analyzer used to analyze data
Analyzer analyzer = new WhitespaceAnalyzer(LuceneVersion.LUCENE_48);
// Create an indexWriterConfig which holds all the configurations to create an instance of the writer
IndexWriterConfig config = new IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer);
// Create the indexWriter with the analyzer and the configuration
IndexWriter indexWriter = new IndexWriter(directory, config);
}
catch(Exception ex)
{
// Handle Lucene exceptions
}
The following example creates documents and adds them to the IndexWriter along with the product information as data.
try
{
// Add the products information that is to be indexed
Product[] products = FetchProductsFromDB();
foreach (var prod in products)
{
// Create a document and add fields to it
Document doc = new Document();
doc.Add(new TextField("ProductID", prod.ProductID.ToString(), Field.Store.YES));
doc.Add(new TextField("ProductName", prod.ProductName, Field.Store.NO));
doc.Add(new TextField("Category", prod.Category, Field.Store.YES));
doc.Add(new TextField("Description", prod.Description, Field.Store.YES));
// Writer is created previously
indexWriter.AddDocument(doc);
}
// Calling commit on the writer saves all the write operations
indexWriter.Commit();
// Dispose the indexWriter after search is performed
indexWriter.Dispose();
}
catch(Exception ex)
{
// Handle Lucene exceptions
}
Once the IndexWriter is used for indexing the data, IndexWriter.Dispose needs to be called to free the resources in use. If a writer is already opened and is not disposed, an exception with type LockObtainFailedException is thrown on reopening it.
DistributedLucene on deleting a document, will not show the results after deletion but it
will maintain the deleted documents. On performing search on the deleted documents; you will be returned with the Hits received as a result of Searcher.Search(query). However you cannot get the content of the received hits since the documents are no longer in the cache store.
Searching Data
Searches are performed after indexing the data. In order to search the data NCacheDirectory is passed to the IndexReader. The instance of the IndexReader is passed to the Searcher. Searcher is responsible for performing search on the data according to the given queries. Lucene provides a wide range of queries and DistributedLucene supports all the Lucene queries.
The provided code below shows searching performed on the indexed data.
try
{
// Open a new reader instance
// The 'applyAllDeletes' is set to true which means all enqueued deletes will be applied on the writer
IndexReader reader = indexWriter.GetReader(true);
// OR
IndexReader reader = DirectoryReader.Open(indexWriter, true);
// A searcher is opened to perform searching
IndexSearcher indexSearcher = new IndexSearcher(reader);
// Specify the searchTerm and the fieldName
string searchTerm = "Beverages";
string fieldName = "Category";
LuceneVersion version = LuceneVersion.LUCENE_48;
Analyzer analyzer = new WhitespaceAnalyzer(LuceneVersion.LUCENE_48);
// Create a query parser and parse the query with the parser
// Analyzer is whitespace analyzer as specified beforehand
QueryParser parser = new QueryParser(version, fieldName, analyzer);
Query query = parser.Parse(searchTerm);
// Returns the top 10000 hits from the result set
ScoreDoc[] docsFound = indexSearcher.Search(query, 10000).ScoreDocs;
// Closes all the files associated with this index
// Please make sure that no operations should be performed after calling this
reader.Dispose();
}
catch(Exception ex)
{
// Handle Lucene exceptions
}
You can call Dispose at the end of every reader instance.
Deviations from Lucene in NCache
API Changes
NCacheDirectory needs to be opened for maintaining indexes instead of
Lucene.Net.Store.Directory.Lucene.Net.Search.TopDocs.TotalHitsrepresents the number of top results achieved as a result of the searching performed. In case of DistributedLucene, this value is converted fromintegertolong. Similarly the values ofLucene.Net.Search.ScoreDocs.Doc,Lucene.Net.Index.IndexReader.NumDocandLucene.Net.Index.IndexReader.MaxDocsare also converted fromintegertolong.
Behavioral Changes
All the write operations performed on the indexes are asynchronous in nature so they are returned on completion of operations in the background. However in case you want to get the information about the number of operations completed at an instance, NCache introduced a
BooleanpropertyOperationsCompletedwhich returns true in case of no more operations to be performed and false otherwise.For Partitioned Replica; whenever a node leaves or joins the cluster, state transfer occurs resulting in the shifting of documents on other nodes. In order to get the latest commits in this case, a new reader instance needs to be opened after state transfer occurs.
Not Supported Lucene API
Given below is a list of Lucene API not supported in DistributedLucene.
IndexSearcherpublic IndexSearcher(IndexReaderContext context, TaskScheduler executor)public Document Document(int docID, ISet<string> fieldsToLoad)public virtual Weight CreateNormalizedWeight(Query query)
IndexReaderpublic static DirectoryReader Open(Directory directory, int termInfosIndexDivisor)public static DirectoryReader Open(IndexWriter writer, bool applyAllDeletes)public static DirectoryReader Open(IndexCommit commit)public static DirectoryReader Open(IndexCommit commit, int termInfosIndexDivisor)public IList<AtomicReaderContext> Leaves
DirectoryReadernew public static DirectoryReader Open(IndexCommit commit)new public static DirectoryReader Open(IndexCommit commit, int termInfosIndexDivisor)public static DirectoryReader OpenIfChanged(DirectoryReader oldReader)public static DirectoryReader OpenIfChanged(DirectoryReader oldReader, IndexCommit commit)public static DirectoryReader OpenIfChanged(DirectoryReader oldReader, IndexWriter writer, bool applyAllDeletes)
CompositeReaderpublic override sealed IndexReaderContext Context
Additional Resources
NCache provides sample application for DistributedLucene on GitHub.
See Also
Lucene Components and Overview
Configure Lucene Query Indexes
SQL Search in Cache
Search Cache with LINQ