One common nightmare among developers and software architects is their sole web server/data source crashing, losing thousands of connected clients, applications, and precious data. With the help of a distributed, load-balanced caching layer such as NCache you can make your application tier highly scalable and available. With the increase in transaction load, you can add more servers. The distributed architecture ensures there is no single point of failure.
NCache is an in-memory distributed data store that provides optimum performance for your applications. The NCache cluster is self-healing and dynamic. It contains nodes that automatically balance the load among themselves without user intervention on every cluster update.
NCache Details NCache Docs Partitioned-Replica
This blog gives you a quick tour of how NCache offers scalability and performance while maintaining 100% uptime. For understanding NCache architecture in detail, you can check this video out:
Maintaining High Availability in NCache Cluster
NCache’s distributed and replicated architecture ensures 100% uptime even if a node goes down unexpectedly. NCache’s peer-to-peer architecture and runtime discovery of clusters and clients with no user intervention ensures such high availability. Moreover, NCache provides intelligent failover support, so the cluster always remains available for all connected clients.
Peer-To-Peer Architecture
NCache provides dynamic cache clustering with a peer-to-peer architecture where there is no single point of failure. A cache cluster has interconnected servers, and it contains a coordinator (senior-most server node) that manages the memberships to the cluster. If the coordinator goes down, the role passes on to the next senior-most server in the cluster. It ensures no single point of failure in cluster membership management.
Runtime Discovery Within Cluster and Clients
Cluster:
Once a server starts, it must know of at least one other server in the cluster. The server contains a list of multiple cache servers, and it tries to connect to anyone of them. Once it connects to a server, it asks that server about the cluster coordinator and asks the coordinator to add it to the membership list of the cluster.
The coordinator adds this new server to the cluster at runtime and informs the other connected servers that a new server has joined the cluster. It also informs the new server about all the members of the cluster. The new server then establishes a TCP connection with all the servers in the cluster.
Client:
Once the client connects to a cache server, it receives the following information from that server at runtime:
- Cluster membership information
- Caching topology information
- Data distribution map
The client uses this information to help determine which cache servers to connect to and how to access the cache based on the caching topology.
Runtime Discovery Within Cluster and Clients
In NCache, the discovery of cluster and client during runtime takes place in the following ways:
Cluster:
As a cluster is a collection of nodes, so once a server starts, it must know of at least one other server in the cluster. The server contains a list of multiple cache servers and tries to connect to anyone of them. Once it connects to a server, it asks that server about the cluster coordinator and asks the coordinator node to add it to the membership list of the cluster.
The coordinator adds this new server to the cluster at runtime and informs the other connected servers that a new server has joined the cluster. It also updates the new server about all the members of the cluster. The new server then establishes a TCP connection with all the servers in the cluster.
Client:
Once the client connects to a cache server, it receives the following information from that server at runtime:
- Cluster membership information
- Caching topology information
- Data distribution map
The client uses this information to help determine which cache servers to connect to and how to access the cache based on the caching topology.
Failover Support
As the NCache cluster is self-healing, it provides failover support within the cluster and for the clients if a server is added or removed at runtime.
- Cluster failover support: The cluster automatically rearranges itself by updating its connections to the other servers upon every cluster update.
- Client failover support: The clients automatically connect to another server in the cluster if there is server disconnection. Similarly, if there is an addition of a server, clients update themselves and can connect to the new server.
For more details on high availability features, head over to our blog High Availability Promised with NCache.
Caching Topologies Self Healing Dynamic Clustering NCache Architecture
Maintenance Mode
NCache supports maintenance mode for its Partitioned of Replica topology. Although the POR topology itself ensures high availability with a replica of each node. However, in case you need to run an upgrade or do a patch update on cache, you need to stop each cluster node one by one. However, stopping a cache node triggers a state transfer within the entire cache cluster resulting in excessive use of resources like Network and CPU, drastically impacting cache availability.
The NCache maintenance mode resolves this issue by giving you the option to stop a node for maintenance. Once a node is stopped, it informs the cluster to halt any state transfer for a specific timeout period. When a cluster undergoes maintenance, the replica of this node will act as the active node and serve the client data requests. Once the node itself re-joins the cluster, it requests data from its replica node. Essentially, maintenance mode saves your cluster the cost of an expensive state transfer process.
NCache Details NCache Docs Maintenance Mode NCache Docs
Attaining Runtime Scalability of NCache Cluster
Since NCache stores your data along with providing advanced features like Pub/Sub messaging and query execution, you can expect to run into memory or computational limit if all your transactions are on one server only. This is why NCache provides seamless linear scaling to handle increasing requests/sec and store more data.
NCache Web Manager makes scaling your environment as simple as clicking on buttons, and voila, you have a dynamic cluster with additional nodes without stopping your clients. The following GIF shows how simple it is to scale your cluster dynamically in NCache:
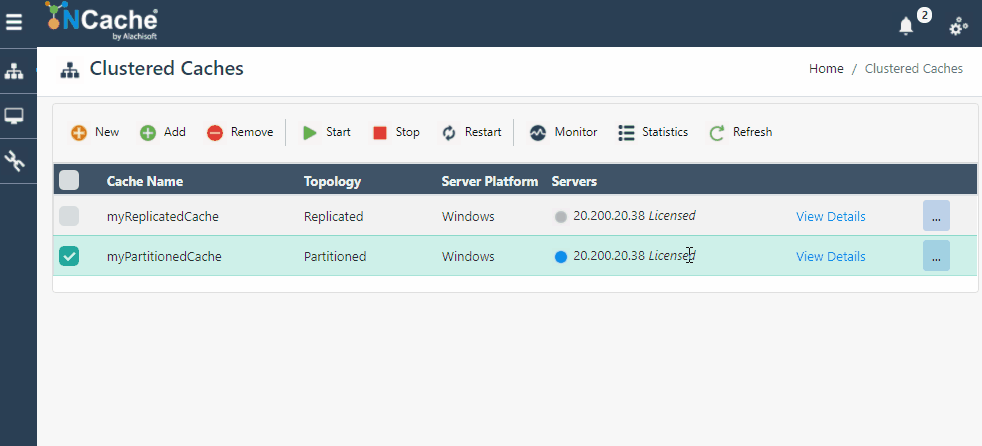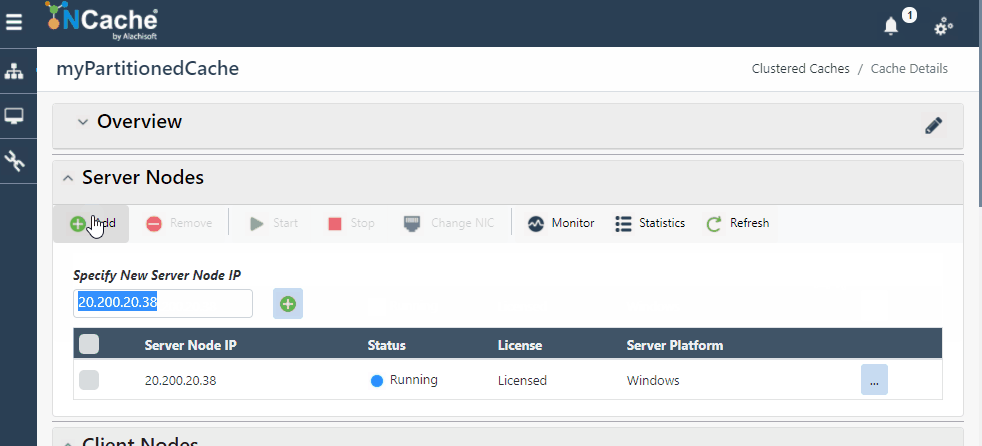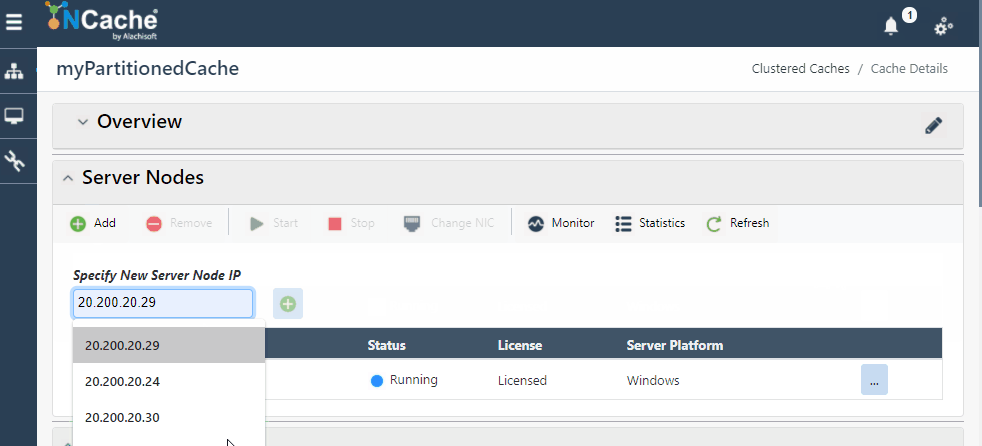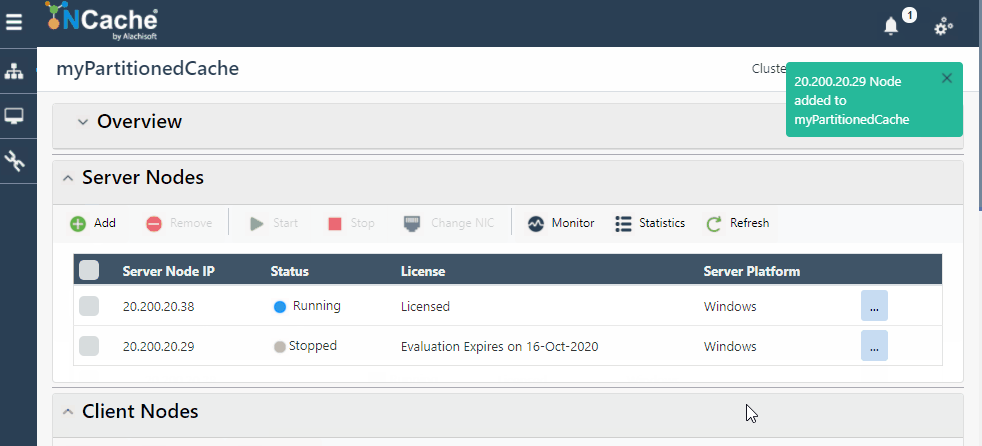
Figure 1: Add Server Node in NCache Cluster
Parallel Operations
NCache has a dynamic cluster that lets clients receive the required data in just one hop because the clients are handled effectively within the cluster without any user intervention. Moreover, the client operations are sent and executed in parallel on all nodes. The results from each node are compiled into a single result, making the operations scalable. It also enhances the performance of the transactions because of parallelism.
Pipelining
With pipelining, NCache reduces network overhead by combining multiple client operations sent in one TCP call to the server. Similarly, the client receives the operation results in a single chunk in one call. It helps to scale operations.
Object Pooling
With object pooling, the NCache server pools the objects and reuses them to prevent invoking the Garbage Collector over and over again. Garbage collection is a performance-intensive task, hence lessening the need to call the GC results in higher performance and scalability of your environment.
Client Cache
NCache offers client cache, a cache on top of the cache, residing where the application resides. As the client cache lies between the application and clustered cache, it is automatically synced and boosts performance, especially for read operations. The use of a client cache cuts down on network overhead.
For more detail, you can check out the blog: Scalability Architecture in NCache – An Insight
NCache Details Client-Side Operations Pipelining in NCache
Conclusion
NCache, being a .NET native distributed caching solution, fits into your application stack seamlessly. It boosts performance tremendously because of object pooling, parallel operations, and the client cache that sits next to your application. Apart from being scalable, it also maintains 100% uptime at all times to ensure the high availability of data and clients.