Caching Topologies for Linear Scalability
NCache provides a variety of caching topologies to enable linear scalability while maintaining data consistency and reliability. The goal of this is to address the needs of applications running with very small two-server caches to very large cache clusters consisting of tens or even hundreds of cache servers. A caching topology is essentially data storage, data replication, and client connections strategy in a clustered cache spanning multiple cache servers.
Below are the main caching topologies that NCache provides:
- Partitioned Cache
- Partition-Replica Cache
- Replicated Cache
- Mirrored Cache (2-Node Active/Passive)
- Client Cache (InProc Speed; Local Cache connected to Clustered Cache)
Reference Data vs. Transactional Data
Reference data is data that doesn’t change very frequently and you cache it to reach over and over again and occasionally update it. Transactional data, on the other hand, is data that changes very frequently and you may update it as frequently as you read it.
Caching a product catalog where prices do not change very frequently is reference data. On the other hand, ASP.NET Core Sessions storage is considered a transactional use because a session is read and updated once on every web request which may happen every few seconds.
In early days, a cache was considered good mainly for reference data because data that changed frequently would become stale and out of sync with the latest data in the database. But, NCache now provides very powerful features that enable the cache to keep its cached data synchronized with the database.
All caching topologies are good for reference data but only some caching topologies are especially better for transactional data. You need to determine how many reads versus writes you'll be doing to figure out which topology is best for you. Additionally, some caching topologies don’t scale as much specially for updates so keep that in mind too.
Below is a list of caching topologies along with their impact on reads versus writes.
- Partitioned Cache (no replication): Very good. Superfast for both reads and writes and also scales linearly by adding servers. Fastest topology but does not replicate data so there is data loss if a cache server goes down.
- Partition-Replica Cache (Most Popular): Very good. Superfast for both reads and writes and also scales linearly by adding servers. Second fastest topology but replicates data for reliability without compromising linear scalability. Best combination of speed/scalability and data reliability.
- Replicated Cache: Very good for smaller environments. Superfast and linearly scalable for reads. Moderately fast for writes in a 2-Node cluster but does not scale as you add more servers because writes are synchronously done on all cache servers.
- Mirrored Cache: Very good for smaller environments. Superfast for reads. Writes are faster than Replicated Cache for 2-Node Active/Passive. But, does not scale beyond this.
- Client Cache: Very good for read-intensive use with all caching topologies. Lets you achieve InProc speed with distributed cache.
Partitioned Cache
Partitioned Cache is the fastest and most scalable caching topology for both reads and writes. It is intended for larger cache clusters and the performance of reads and writes remains very good even under peak loads. However, it does not replicate data and hence there is data loss if a cache server goes down.
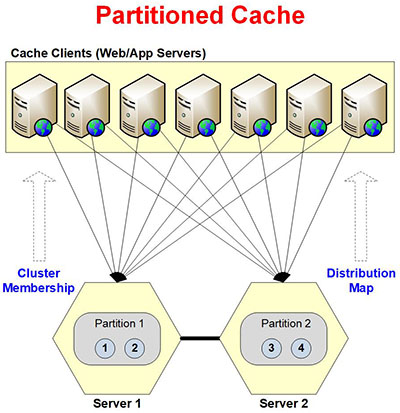
Here are some characteristics of Partitioned Cache.
- Dynamic Partitions: cache is divided into partitions at runtime with each cache server having one partitions. There are a total of 1000 buckets per clustered cache that are evenly distributed to all partitions. Adding / removing cache server results in creation / deletion of partitions at runtime. The buckets assignment to partitions does not change when data is being added to the cache. Instead, it only changes when partitions are added or deleted or when data balancing occurs (see below).
- Distribution Map: the cache cluster creates a Distribution Map that contains information about which buckets exist in which partitions. Distribution Map is updated whenever partitions are added or deleted or when data balancing occurs (see below). Distribution Map is propagated to all the servers and clients. The clients use this to figure out which cache server to talk to for reading or writing a certain cached item.
- Dynamic Data Balancing: since all the buckets are actually HashMap buckets where data is stored based on a Hashing algorithm on the keys, there is a chance that some buckets may have more data than others depending on what keys were used. If this imbalance crossed a configurable threshold, NCache automatically shifts buckets around to balance out this load.
- Clients Connect to ALL Partitions: clients connect to all the cache servers so they can directly read or write data in one request from the server. If a client’s connection with a cache server goes down, then it asks one of the other servers to read or write a cached item that exists on the server which it cannot access. And, that server helps the client achieve that.
Partition-Replica Cache
NOTE: everything mentioned in Partitioned Cache is true here too.
Just like Partitioned Cache, Partition-Replica Cache is extremely fast and linearly scalable caching topology for both reads and writes. It is intended for larger cache clusters and the performance of reads and writes remains very good even under peak loads. On top of this, Partition-Replica Cache also replicates data and hence there is no data loss even if a cache server goes down.
Partition-Replica Cache is our most popular caching topology because it gives you the best of both worlds, performance / linear scalability and data reliability.
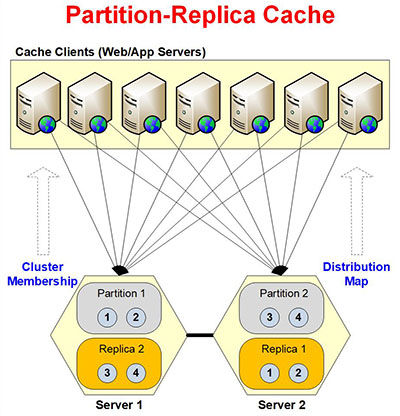
Below are some of the characteristics of Partition-Replica Cache.
- Dynamic Partitions: same as Partitioned Cache.
- Dynamic Replicas: when partitions are created or deleted at runtime, their Replicas are also created or deleted. Replicas are always on a different cache server and there is only one Replica for a Partition.
- Async Replication: by default, replication from Partition to Replica is asynchronous. This means the client can add, update, or delete any data in the Partition and all these operations get queued up. And, then their replicated in BULK on the Replica. This improves performance but has the slight risk of data loss in case a Partition goes does and not all the updates had been replicated to the Replica. But, in most situations, this is perfectly fine.
- Sync Replication: if your data is very sensitive (e.g. financial data) and you cannot afford to ever have stale data, then you can choose “Sync Replication” option in the configuration. When selected, all write operations are synchronously performed on both Partition and Replica until they’re considered completed. This way, if the operation fails on the Replica, it also fails on the Partition. And, you can be guaranteed that all data in the cache (in both Partition and Replica) is always consistent. However, this has performance implication as it is slower than Async Replication.
- Distribution Map: same as Partitioned Cache.
- Dynamic Data Balancing (Partitions & Replicas): same as Partitioned Cache. However, in Partition-Replica Cache, data balancing also occurs in the Replicas when the partitions are data balanced.
- Clients Connect to ALL Partitions: same as Partitioned Cache. Additionally, in Partition-Replica Cache, the clients only talk to partitions and not their replicas. This is because replicas are passive and only partitions talk to their replicas when replicating data to them.
Replicated Cache
Replicated Cache provides data reliability through replication on two or more cache server. It is very fast and scalable for reads. But, it does not scale for writes because they’re synchronous to all the servers in the cluster. For a 2-node cluster, the writes are faster than your database but not as fast as Partition-Replica Cache. For 3 or more server clusters, the writes performance degrades and eventually becomes unattractive.
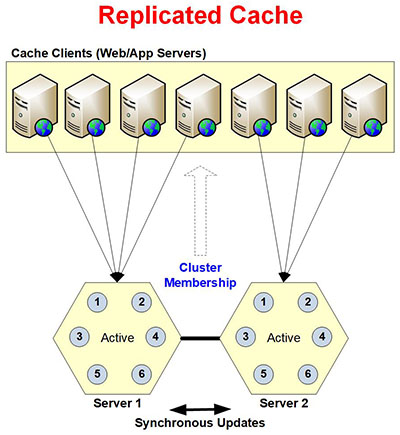
Below are some of the characteristics of Replicated Cache.
- Dynamic Replicated Nodes: you can add or remove cache servers at runtime to an exist cache without stopping the cache or your application. Newly added server makes a copy (Replica) of the entire cache on to itself. And, server that is removed updates cluster membership and all of its clients move to other servers.
- Entire Cache on Each Node: entire cache is copied to every server in the cluster.
- Reads are Scalable: reads are superfast and scalable when you add more servers. However, adding more servers does not increase the cache size as the newly added server is just another copy of the entire cache.
- Writes are Synchronous: writes are very fast for a 2-Node cluster and faster than your database. But, writes are synchronous meaning each write operation does not complete until all cache servers are updated synchronously. Due to this, writes are not as fast as other topologies and their performance degrades when you increase cluster size beyond 2-Node.
- Client Connects to One Server Only: each cache client only connects to one server in the cluster based on a load-balanced algorithm determined by the cache servers. If this cache server goes down, the client connects to next server in the list. You can also manually specify server to connect to in the cache configuration file if you don’t want to use load balancing.
Mirrored Cache
Mirrored Cache is a 2-Node Active/Passive cache cluster intended for smaller environments. It provides data reliability through asynchronous replication/mirroring from Active Node to Passive Node. It is very fast for both reads and writes (in fact writes are faster than Replicated Cache) but does not scale beyond this 2-Node Active/Passive cluster.
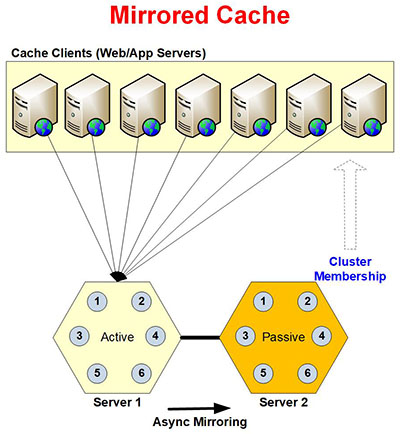
Below are some of the characteristics of Mirrored Cache.
- 1 Active & 1 Passive Server: Mirrored Cache only has two servers. One is Active and the other is Passive. They both have a copy of the entire cache. If the Active Server goes down, the Passive Server automatically becomes Active. And, if the previously downed Active Server comes back up, it is treated as a Passive Server unless you change this designation through admin tools at runtime.
- Clients Connections with Failover Support: each cache client only connects to the Active Server in the cluster to do their read and write operations. If this Active Server goes down, all the clients automatically connect the Passive Server that has become Active by now. This failover support ensures that Mirrored Cache is always up and running even if a server goes down.
- Async Mirroring: any writes done on the Active Server are asynchronously mirrored / replicated to the Passive Server. This ensures that the Passive Server is always synchronized with the latest data in case the Active Server goes down and the Passive Server has to become Active. Async mirroring also means faster performance because multiple writes are performed as a BULK operation on the Passive Server.
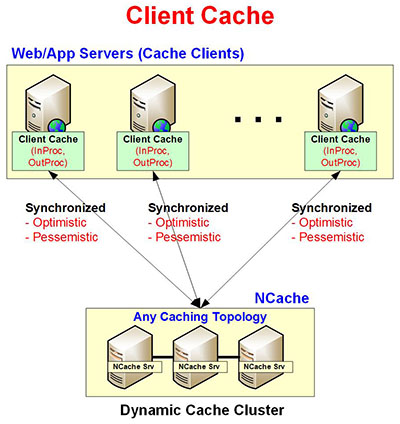
Client Cache (InProc Speed)
Client Cache is local to your web / app server and sits very close to your application and lets you cache data that you’re reading from the distributed cache (any caching topology). You can see this as a "cache on top of a cache" and greatly improves your application performance and scalability even further. If you use Client Cache in InProc mode, you can achieve InProc speed.
While being local to your application, a Client Cache is not a stand-alone. Instead, it is always synchronized with the clustered cache. This ensures that data in the client cache is never stale.
Below are some of the characteristics of Mirrored Cache.
- Good for Read Intensive Cases: Client Cache is good only if you have a read-intensive use case where the number of reads are many times more than writes. If number of writes are the same as reads then Client cache is actually slower because a write involves updating it in two places.
- Faster Speed like a Local Cache (InProc / OutProc): a Client Cache exists either inside your application process (InProc mode) or local to your web / app server (OutProc mode). In either case, it boosts your application performance significantly as compared to just fetching this data from the clustered cache. InProc mode lets you cache objects on your “application heap” which gives you “InProc Speed” that cannot be matched by any distributed cache.
- Not a Stand-Alone Cache: Client Cache may be a Local Cache but it is not a stand-alone cache. Instead, it keeps itself synchronized with the clustered cache. What this means is that if another client updates data in the clustered cache that you have in your Client Cache, the clustered cache notifies the Client Cache to update itself with the latest copy of that data. And, this is done asynchronously but immediately.
- Optimistic / Pessimistic Synchronization: By default, Client Cache uses Optimistic Synchronization which means that NCache client assumes that whatever data the Client Cache has is the latest copy. If Client Cache doesn’t have any data, the Client fetches it from the Clustered Cache, puts it in the Client Cache, and returns it to the client application. Pessimistic Synchronization means the Cache Client first checks the Clustered Cache whether it has a newer version of a cached item. If it does, then the client fetches it, puts it in the Client Cache, and returns it to the client application. Otherwise, it returns whatever is in the Client Cache.
- Plug-in without Any Code Change: the best things about Client Cache is that it involves no code change in your application. Instead, you simply plug it in through a configuration change. And, NCache Client API behind the scenes knows what to do about using the Client Cache.